
This article will guide you through deploying and configuring the supervisor using VPC networking with an NSX-integrated load balancer. We will then explore three ways to deploy vSphere Kubernetes Service within VPC networking.
Navigation
Pre-requirements
In order to deploy the supervisor with VPC networking, you first must have configured centralised connectivity with an active/passive tier-0 gateway cluster. This can be within the default or another NSX project. For this article, everything will be deployed into the default project.
Each Tanzu Kubernetes node will need a /24 CIDR for pod addressing.
If you configure routed pods with public VPC subnets, they will be consumed from the VPC External IP Blocks. Ensure that you have enough space allocated; if not, add a larger CIDR to accommodate. For example, a /20 subnet will allow for 8 nodes, i.e. 3 control plane and 5 workers. If you don’t have the correct sizing, the cluster will deploy but will not work.
If you configure non-routed, encapsulated pods or with VPC private subnets, the same rules apply, but the allocations come from the Private VPC IP CIDRs allocated to the VPC selected.
The compute cluster has a 1-1 relationship with the supervisor and must be enabled for vSphere HA and DRS.
You’ll need a management network with at least 5 addresses, either as a distributed port group on VDS, or a VPC subnet. Three addresses are for the nodes, 1 spare for upgrades and another one for the cluster VIP.
Architecure
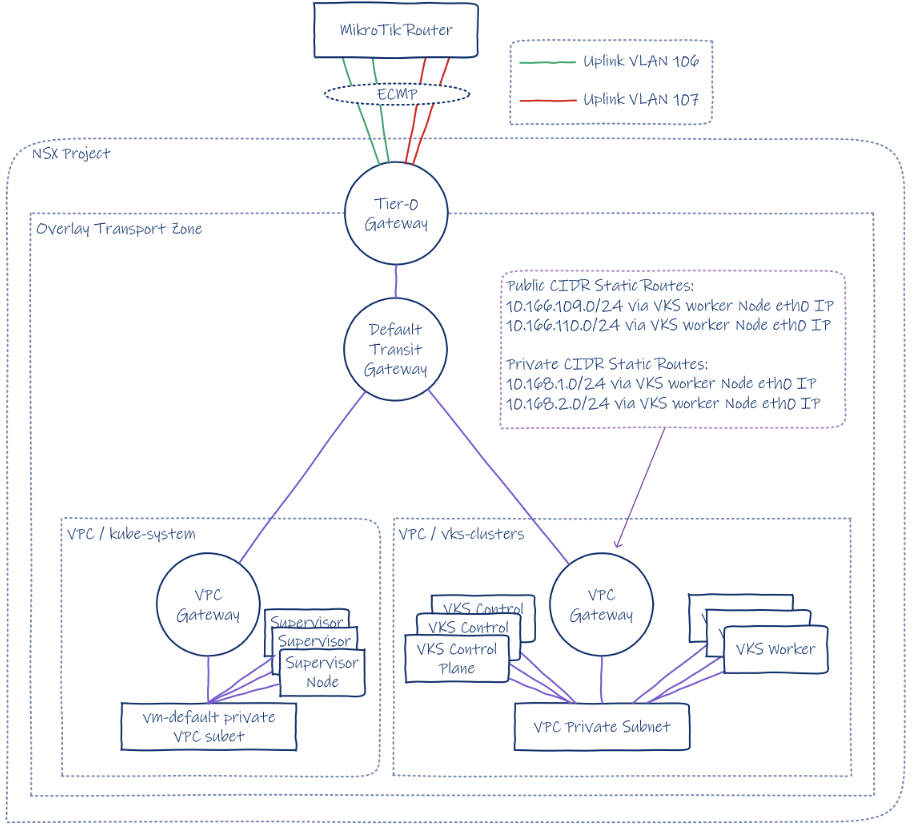
Below is a topology diagram of the deployment. We will be deploying the supervisor into its own private VPC subnet, and the three VKS clusters will deploy into a second private VPC subnet. The box on the right shows an example of one of them. At a high level, all three are the same, the main difference being whether static routes are created on the VPC gateway and to what CIDR.
To save resources in the lab, we will only be deploying one supervisor node. Within each of the VKS clusters, only one control plane and one worker will be deployed. In a production environment, you would deploy three supervisor and VKS control plane nodes in the same zone or, if you have the compute resources, across three zones. Additionally, you would deploy enough workers to handle your application, including resilience and reserve capacity.
Supervisor Deployment
From the menu, select Supervisor Management

Click the get started wizard. If you are repeating a prior install, you can simply upload a JSON file. At the end of the get started wizard, you can export the configuration and reuse it. Just like with the VCF installer. The one we will export later is on GitHub here.
Select VCF Networking with VPC and click next.

For our lab, we only have one zone. We will select cluster deployment and the lab cluster, which is already enabled for HA and DRS. If these were not configured, the cluster would be listed as incompatible.
Enter a supervisor’s name. I will be using “home-m01-cl01-sup01”.
If you also select “Enable control plane high-availability”, then three nodes will be deployed; if not, then only one will be. You can easily change from 1 to 3 later. Given this is a lab on a single box, I will not check this box. Click next.

For storage, select the VCF storage policy you want. I selected the default one for VCF. This will get assigned as a storage class in the supervisor cluster. Click next.

Select the mode and network you want to attach for management; this will ultimately become eth0 on each of the supervisor nodes and is where the VIP lives for the Supervisor Kubernetes API. For my lab, I precreated a public VPC subnet with DHCP and also reserved the first address for the VIP.

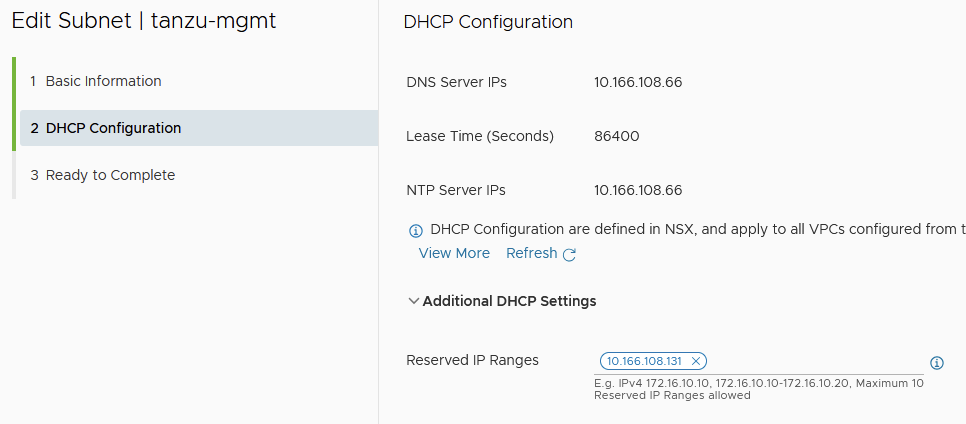
I selected these options for the management network. DNS and NTP are both on my MikroTik router outside of any virtual machine-based domain controllers, etc. It means my system happily boots and works with the domain controller being offline. Click next.

On the next screen, you can see the external IP blocks, which are used for public routed subnets, SNAT addressing, Ingress and services of type LoadBalancer.
The Supervisor control plane will allocate one SNAT IP and one common Kubernetes ingress IP for each namespace and one unique load-balancer IP for each LoadBalancer type Service. External IP Blocks must not overlap with Service CIDR or private CIDRs in the same VPC.
For the private CIDR range, I will use 10.168.0.0/16. You can also leave it as the default if you prefer. Whatever you use must not overlap with Service CIDR or External IPs in the same VPC. At least one provided CIDR must be larger than 64 IPs (Subnet Mask /25 or larger).
The Kubernetes ClusterIP Services CIDR block is for use within the Kubernetes cluster only. It needs to not overlap with IPs of Supervisor Management components (VC, NSX, ESXs, Management DNS, NTP) and other datacenter IPs communicating with workloads. The default is fine.
For NTP/DNS, I will use my MikroTik router again. Click next.

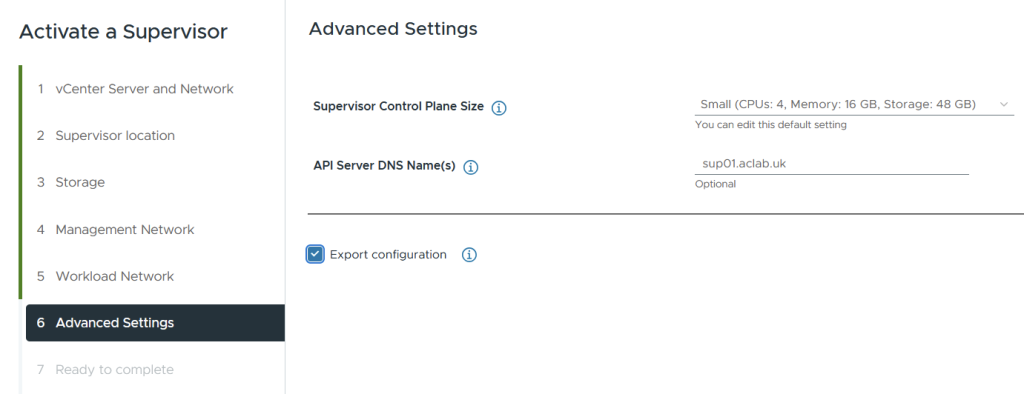
Under advanced, select the initial size for the control plane nodes. Tiny hasn’t got much reserve, so go with small as a minimum. You can easily change this later. My alternative DNS name for the SAN certificate is sup01.aclab.uk. Make sure to export the configuration for any later re-deployments.
The JSON-exported file is saved in my VCF GitHub repository.
Click next.
Review the settings and modify as needed, then click finish.

Confirm Supervisor Deployment
If you SSH to the vCenter server, you can run the command below to grab the root password for the supervisor. If you log in, you can run kubectl commands locally, which is super handy. You will also have a cluster-admin role binding.
/usr/lib/vmware-wcp/decryptK8Pwd.pyThe Workload Control Plane (WCP) service on vCenter is responsible for the deployment of the supervisor, the configuration of NSX, etc. You can control the service and check the logs with the following commands.
## restart
service-control --restart wcp
## check status
service-control --status wcp
## check logs
tail -f /var/log/vmware/wcp/wcpsvc.logFrom NSX manager, you can review the load balancer configuration from inside the kube-system VPC. This VPC is where the supervisor nodes attach.

You’ll also see a SNAT rule, with an address assigned from the external IP blocks.

From vCenter, you can see the supervisor node. Once the CNI is initiated, it will have an eth0 NIC attached to the management VPC public subnet, and a second eth1 NIC connected to the kube-system VPC private subnet.
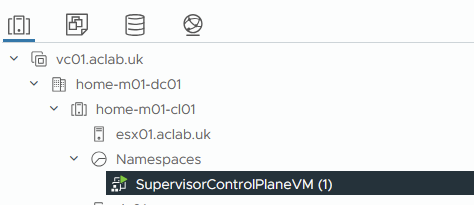
A content library is automatically created, which includes the OVA’s for the supervisor and VKS nodes. Although you can rename this, if you did a re-deploy it will re-create it with this name again. So, it’s probably best to just leave it as-is.

From the supervisor management page, you can watch it complete the install.

Once the supervisor node is configured, it will configure the ESXi host by installing Spherelet, which is the Kubernetes agent which talks to Kube-Scheduler inside the Supervisor nodes.

Eventually everything will be complete.
Set up Client Tools
If you connect to the API address on HTTPS, you will be presented with a page where you can download the VCF CLI. This replaces kubectl vsphere as in prior versions. Download the flavour you need. In my case, I run Fedora in WSL.

Run the following to set up the VCF and Kubectl CLI and to connect to the Supervisor.
## extract and install cli tools
tar -xvzf vcf-cli.tar.gz
sudo mv vcf-cli-linux_amd64 /usr/local/bin/vcf
rm vcf-cli.tar.gz
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo mv kubectl /usr/local/bin/
## confirm cli install
vcf version
kubectl version
## sort auto complete and 'k' alias for kubectl
sudo dnf install bash-completion -y
vcf completion bash > $HOME/.config/vcf/completion.bash.inc
printf "\n# VCF shell completion\nsource '$HOME/.config/vcf/completion.bash.inc'\n" >> $HOME/.bashrc
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
sudo chmod a+r /etc/bash_completion.d/kubectl
echo 'alias k=kubectl' >>~/.bashrc
echo 'complete -o default -F __start_kubectl k' >>~/.bashrc
source ~/.bashrc
## login to supervisor
vcf context create sup01 --endpoint sup01.aclab.uk --username administrator@vsphere.local --insecure-skip-tls-verify
## switch to the supervisor context
vcf context use sup01
## show nodes, you should see the supervisor node and the esxi worker node running spherelet
kubectl get nodes -o wide

In this example, I’ve logged in before the ESXi host has been configured.

Once that side finishes, you will see the ESX host as a worker node. You can check the Spherelet service with the following commands:
/etc/init.d/spherelet status
tail -f /var/log/spherelet.logOnce all green, we are done.


Deploy Supervisor Services
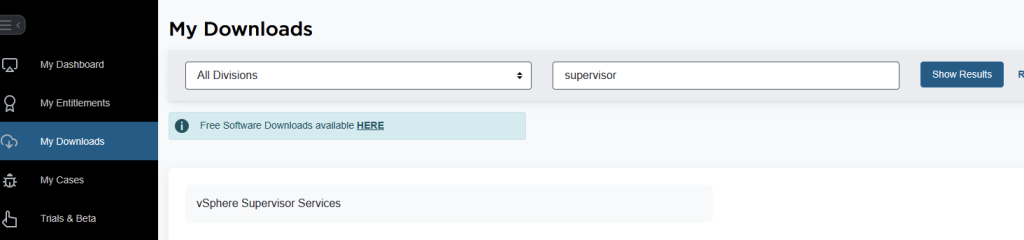
At this point, we want to upgrade the VKS supervisor service and also install the local consumption interface. To do this, we need to log in to the Broadcom portal. Click My Downloads, then search for supervisor. Click vSphere supervisor services.
Download the YAML file for vSphere Kubernetes Service and Local Consumption Interface. I’m running 9.0.2, so I can download the latest. If you’re not sure, check the interop matrix and also the supervisor services GitHub page. Between those two, you can figure out compatibility.


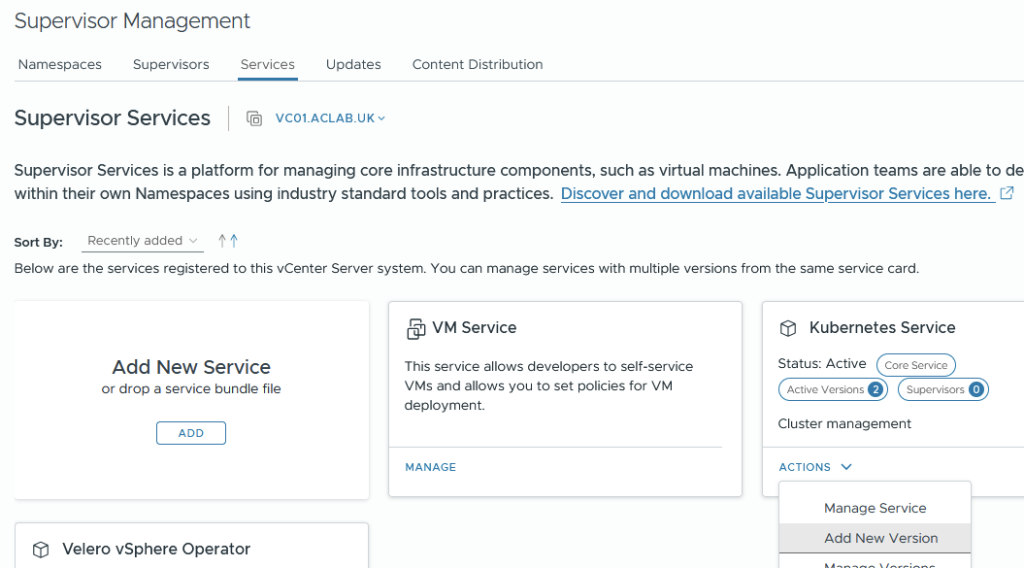
Once you have the YAML files, from supervisor management > services > select actions on Kubernetes Service and add a new version.
Upload the YAML file we downloaded, and click finish.


Next, go into supervisor management > supervisors > select the supervisor > configure > overview within supervisor services. Select Kubernetes service, then click manage.

Select the newer version.

Ignore the warning about only having one supervisor node, and complete the wizard.

Wait for the reconciliation process to complete; it can take a few minutes.

You’ll need to wait until all of these pods are restarted with the new versions.
watch kubectl get pods,deploy,ds -n svc-tkg-domain-c10
Once complete, we will want to install the local consumption interface, which gives better Kubernetes visibility from vSphere. From supervisor management > services > click add new service.

Upload the consumption interface YAML file, and click finish.

From supervisor management > supervisors > select the supervisor > configure > overview > click available and then install the local consumption interface.

Complete the wizard, leaving everything as the default.

Wait for the reconciliation process to complete.

The resources tab on a namespace will now show more information.

Deploy vSphere Kubernetes Service
Next, we need to deploy VKS services, which are the guest-based Kubernetes clusters. The supervisor is the management cluster, and the VKS clusters are the workload clusters. They have their own control plane with a unique etcd and dedicated workers.
Deploy VKS Namespace
Next, we need to create a namespace as a home for the VKS clusters. You can create multiple of these and give granular permissions to each, or, for example, have a single shared one. In my lab, I just have a shared “vks-clusters” namespace, to which all VKS clusters reside.
From supervisor management > namespaces > click new namespace.

Select the supervisor

Enter a DNS conformant name; you can override the networking here to pick another VPC or create a new one with a particular subnet size. In our case, we are just accepting the defaults.

Review the settings and click finish

This will create a new VPC with a private subnet, as well as a SNAT rule, assigned IP and a Load Balancer in NSX.



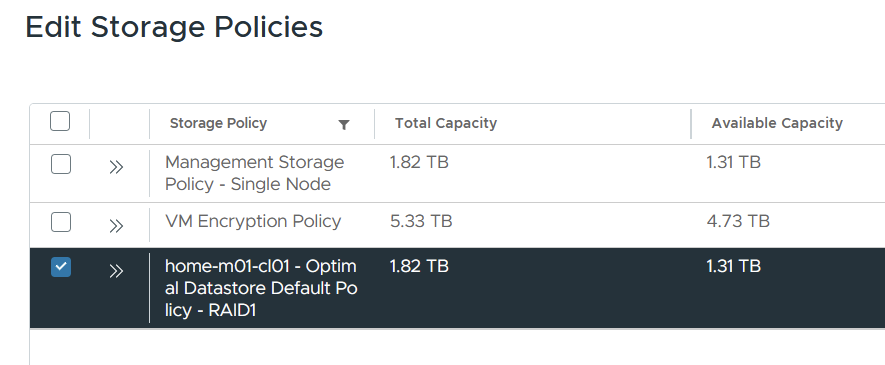
Go to supervisor management > click the vks-clusters namespace. On the summary page, add storage and select the VCF storage policy.
From the VM service tile, click Add VM class. These are the allowed sizes for the VKS nodes. In my lab, we will be using best effort small.

VKS Deployment Paths
Now we want to deploy the VKS clusters; we will be installing three to showcase various pathways.
| Pathway | Description |
| Default Antrea CNI with no-SNAT and No Encapsulation, pods will use a public VPC subnet Download YAML Specification | With this option pods are routable by way of static routes created on NSX, pointing at eth0 on each Kubernetes node. We are assigning pods into a public VPC subnet, so routing only from other VPC’s and is advertised to the external network via the transit gateway and tier-0 gateway. |
| Routed Antrea CNI with no-SNAT and No Encapsulation, pods will use a private VPC subnet Download YAML Specification | With this option pods are routable by way of static routes created on NSX, pointing at eth0 on each Kubernetes node. We are assigning pods into a private VPC subnet, so routing only works inside the VPC. |
| Default Antrea CNI with SNAT and Encapsulation Download YAML Specification | With this option pods are not routable, instead the load balancer in NSX will attach to the private VPC subnet for getting to services inside VKS. |
Connect to VKS Cluster Namespace
Log in to the supervisor and connect to the vks-clusters namespace we just added. When you do a refresh, it may see that an existing token exists, in which case you won’t get one for vks-clusters.

You can either override the context for sup01, delete and re-create the contexts or modify the YAML files to include a default namespace. The choice is yours. Unfortunately, I couldn’t find the vcf auth token to remove it.
## change the namespace on the sup01 context
kubectl config set-context sup01 -n vks-clusters
## delete and recreate
vcf context delete sup01
vcf context create sup01 --endpoint sup01.aclab.uk --username administrator@vsphere.local --insecure-skip-tls-verify
vcf context use sup01:vks-clusters
Deploy All VKS Types
Once in the vks-cluster namespace, create the VKS clusters. First, enter the folder where all three YAML files are, then simply run this one command, which will apply all YAML files in the directory.
kubectl apply -f .
Give it some time, and all three clusters will be deployed. The control plane node is deployed, and then the worker node.

Three private VPC subnets will be added.

For the two clusters using routed pods, static routes will exist in NSX. Below shows routes to private subnets and public subnets, which are the two routed pod variations we deployed.

NSX load balancer will have a virtual server per Kubernetes VIP.
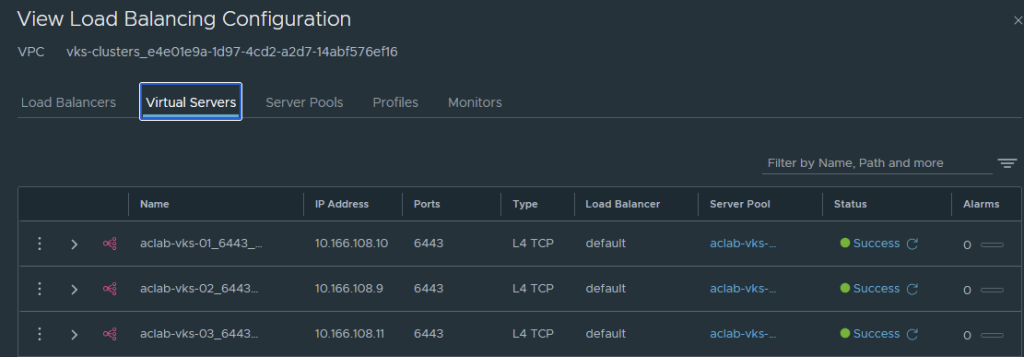
Connect to each VKS Cluster
Next, log in to each VKS cluster by creating the relevant contexts.
vcf context create aclab-vks-01 --endpoint sup01.aclab.uk --username administrator@vsphere.local --insecure-skip-tls-verify --workload-cluster-name aclab-vks-01 --workload-cluster-namespace vks-clusters
vcf context create aclab-vks-02 --endpoint sup01.aclab.uk --username administrator@vsphere.local --insecure-skip-tls-verify --workload-cluster-name aclab-vks-02 --workload-cluster-namespace vks-clusters
vcf context create aclab-vks-03 --endpoint sup01.aclab.uk --username administrator@vsphere.local --insecure-skip-tls-verify --workload-cluster-name aclab-vks-03 --workload-cluster-namespace vks-clustersOnce done, you will have a context for the supervisor namespace, and another for the VKS cluster itself.

Validate Antrea Routed Pods with Public Subnet
To login run the following command.
vcf context use aclab-vks-01:aclab-vks-01You can validate the pod networking CIDR by running the command below. This returns the CIDR for each node, the subnet shown aligns to the VPC External IP Blocks, which is correct as this VKS cluster YAML spec is configured for routed pods with a VPC public subnet.
kubectl get nodes -o yaml | grep podCIDR:
As it’s public, the subnet is exposed to the external network via the VPC gateway > Transit Gateway and Tier-0 Gateway. The route table on my MikroTik router has paths to each of the external IP’s on each NSX edge in the Tier-0 edge cluster. The passive edge will prepend its AS three times, so only the active edge will be used for routing.

The static routes are advertised because the route redistribution policy in NSX has static routes added against the BGP protocol.

At this point, we can deploy a basic application, for example, a minimal nginx unprivileged deployment, which will work with a restricted pod security policy. Once deployed, grab a pod address.
## deploy application
kubectl apply -f nginx-unprivileged-minimal.yaml
## grab the pod address
kubectl get pods -n app01-dev -o wide
From my machine outside of NSX, I can connect directly to the pod that is running. This shows that routable pods work. There is no encapsulation or source NAT required, as NSX, as the SDN is handling routing.

Note, the second pod, which is pending, is intentional; if you look at the YAML manifest, there is pod anti-affinity configured, which will only schedule the pod if on different nodes. Given that I only have one node, we only have one pod scheduled. If you run the below, you will see what is going on.
## note the pod is spawned from a deployment so the numbers at the end will be different in your environment
kubectl describe pod -n app01-dev nginx-example-01-55f4b6b897-pdpvm
Validate Antrea Routed Pods with Private Subnet
To login run the following command.
vcf context use aclab-vks-02:aclab-vks-02You can validate the pod networking CIDR by running the command below. This returns the CIDR for each node; the subnet shown aligns to the Private VPC IP CIDRs, which is correct as this VKS cluster YAML spec is configured for routed pods with a VPC private subnet.
kubectl get nodes -o yaml | grep podCIDR:
As it’s private, the subnet is not exposed to the external network and is only routable within the VPC itself.
Static routes exist in NSX in order for the intra-VPC traffic to reach the pods.

At this point, we can deploy a basic application, for example, a minimal nginx unprivileged deployment, which will work with a restricted pod security policy. Once deployed, grab a pod address.
## deploy application
kubectl apply -f nginx-unprivileged-minimal.yaml
## grab the pod address
kubectl get pods -n app01-dev -o wide
From my machine outside of NSX, I cannot connect. To reach the application, we either need to be inside the vks-clusters VPC or plumb in external connectivity. To do that quickly, we can patch the service to be of type LoadBalancer, which will create L4 connectivity via the NSX load balancer. A better route would be to set up Gateway API or Ingress, which will also attach to a load balancer but at Layer 7. I will say more on this in another article; for now, we can run the below to connect at L4 via NSX.
## expose the service using NSX load balancer
kubectl patch svc nginx-example-01-svc -n app01-dev -p '{"spec": {"type": "LoadBalancer"}}'
## confirm an external IP is allocated from NSX
kubectl get svc -n app01-devAs you can see, an address has been assigned from the VPC External IP Blocks.

Hit this address via an external browser on HTTP 80, and it will connect.

You may have noticed that the pod port in the prior example is 8080, and now the service is 80. This is because the service object is on 80, which connects to the pod on 8080.

Note, the second pod, which is pending, is intentional; if you look at the YAML manifest, there is pod anti-affinity configured, which will only schedule the pod if on different nodes. Given that I only have one node, we only have one pod scheduled. If you describe the pending pod, you will see what is going on.
Validate Antrea Encapsulated Pods
To login run the following command.
vcf context use aclab-vks-03:aclab-vks-03You can validate the pod networking CIDR by running the command below. This returns the CIDR for each node; the subnet shown aligns to the cidrBlocks spec inside the VKS YAML.
kubectl get nodes -o yaml | grep podCIDR:
As this is technically a GENEVE overlay within the Kubernetes node, the subnet is not exposed to the external network and is only routable within the Kubernetes cluster itself. No static routes exist in NSX.
At this point, we can deploy a basic application, for example, a minimal nginx unprivileged deployment, which will work with a restricted pod security policy. Once deployed, grab a pod address.
# deploy application
kubectl apply -f nginx-unprivileged-minimal.yaml
## grab the pod address
kubectl get pods -n app01-dev -o wide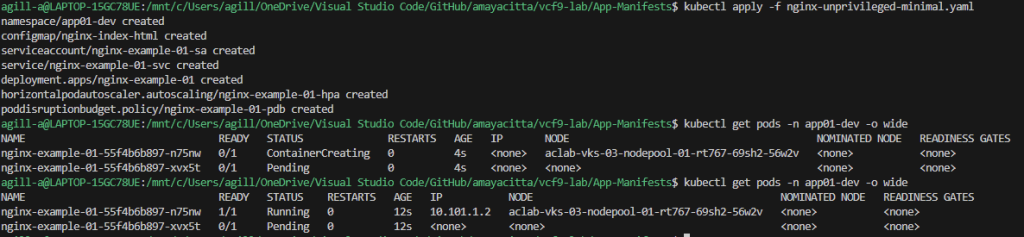
From my machine outside of NSX, I cannot connect. To reach the application, we either need to be inside the Kubernetes cluster or plumb in external connectivity. To do that quickly, we can patch the service to be of type LoadBalancer, which will create L4 connectivity via the NSX load balancer. A better route would be to set up Gateway API or Ingress, which will also attach to a load balancer, but at Layer 7. I will say more on this in another article; for now, we can run the below to connect at L4 via NSX.
## expose the service using NSX load balancer
kubectl patch svc nginx-example-01-svc -n app01-dev -p '{"spec": {"type": "LoadBalancer"}}'
## confirm an external IP is allocated from NSX
kubectl get svc -n app01-devAs you can see, an address has been assigned from the VPC External IP Blocks.

Hit this address via an external browser on HTTP 80, and it will connect.

You may have noticed that the pod port in the first example is 8080, and now the service is 80. This is because the service object is on 80, which connects to the pod on 8080.
Note, the second pod, which is pending, is intentional; if you look at the YAML manifest, there is pod anti-affinity configured, which will only schedule the pod if on different nodes. Given that I only have one node, we only have one pod scheduled. If you describe the pending pod, you will see what is going on.
Conclusion
This concludes the article on Tanzu with VPC networking and NSX classic load balancer. I hope it’s been helpful.